
To enable better data availability and more efficient analytics, HCLS organizations are increasingly investing in cloud-based data warehouses. A data warehouse is essentially a data management system designed to support business intelligence initiatives. It serves as a centralized repository where information is collected from multiple sources, transactional systems, and relational databases.
Having all health-related data easily accessible from one place enables hospitals and clinicians to better monitor population health, develop personalized care plans, and improve patient outcomes. And being cloud-native, such data warehouses bring the benefits of elasticity and almost infinite scalability to accommodate the growing amounts of health data.
A modern healthcare data warehouse typically consists of four core components: data acquisition, data staging, data storage, and data access.
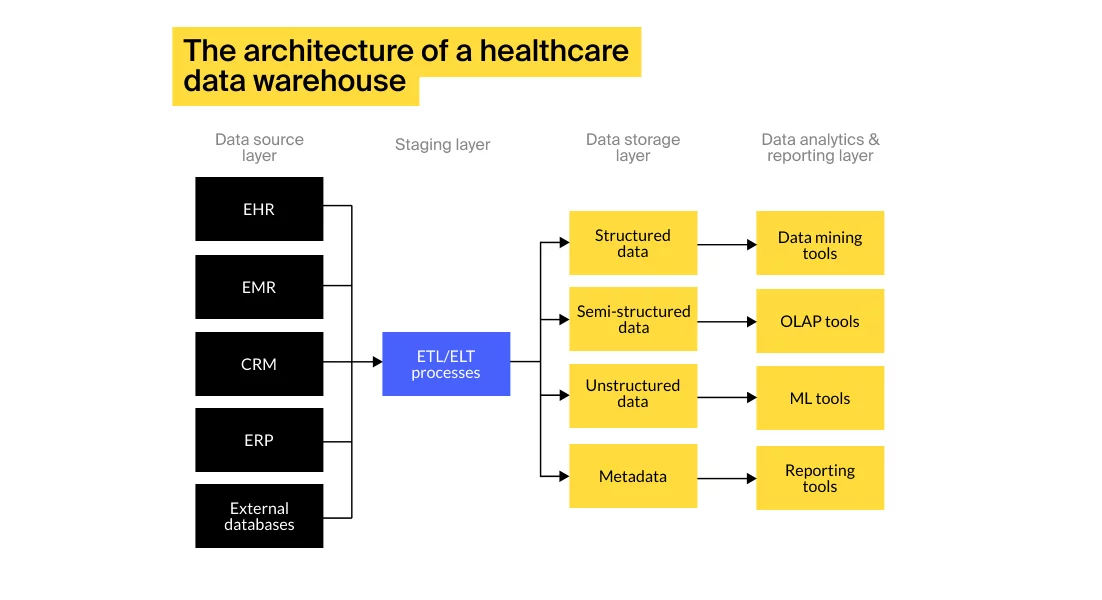
Source: Itrex
Just like with any enterprise-grade system or IT solution, when designing a healthcare data warehouse, the primary factor to be taken into consideration is the needs of end users — healthcare providers and life science organizations.
Healthcare data sources provide petabytes-worth of information — patient, financial, pharmaceutical, clinical research, as well as data from wearables and IoT devices. This data comes in a variety of forms and formats, from structured, numeric data to unstructured written texts, radiology images, and more. One approach to power efficient data extraction and consolidation is to use semantic technologies that enrich data by adding context and facilitate more meaningful integration.
A robust data integration approach also needs to take into account other factors like the intended purpose (operational decision making or research only) and primary data users. This will further inform the decision what sources of data need to be integrated to better serve analytics purposes.
The data model is the backbone of a data warehouse and it has a significant effect on time-to-value and system adaptability. Basically, there are two approaches — top-down and bottom-up.
In a top-down model, “atomic” data is stored at the lowest level of granularity. Data elements are assigned specific categories and dimensions that will be represented in a schema, hence this approach requires a very detailed specification of how the data will be used. Although this model is comprehensive, it is very inflexible if new data that needs to enter the system does not fit into the predefined categories and dimensions.
A bottom-up model suggests creating smaller data marts to address specific business or clinical needs. These data marts pull information from a data superset into individual applications tailored to the needs of specific departments or areas of research. This is a cost-effective method to start a data warehousing project but the drawback is that large-scale analysis or reporting across these data marts is extremely difficult.
To avoid the pitfalls of the above-mentioned models, data scientists advocate a late-binding approach to designing data warehouse architecture in healthcare. In the late-binding process, atomic data is taken from source systems into source marts and later data marts with minimum remodeling. Instead of binding data to any volatile business rules at an early stage, you can bind data for a specific use case in a particular data mart, which gives you maximum flexibility.
Of all personal data, health data is considered most sensitive. In addition to routine clinical information like medical history and lab results, health information systems contain names, addresses, health insurance card numbers, and other confidential information. Any security flaw in a healthcare data warehouse could lead to unauthorized access and threaten patient privacy.
To keep protected health information (PHI) secure and private, data warehouse development requires a security-first approach based on security best practices and policies like data encryption and data pseudonymization for patient de-identification. Other security measures include multi-factor authorization and granular access control with custom roles and permissions.
In addition, any data storage that handles health records must comply with the Health Insurance Portability and Accountability Act (HIPAA). Hence, when building a cloud-based healthcare data warehouse, it’s important to choose a HIPAA-compliant cloud storage service provider.
Since a healthcare data warehouse underpin clinical decision-making, glitch-free performance is imperative. This is however no easy task to achieve since a data warehouse processes diverse sets of data and answers ad hoc queries from multiple users.
To ensure fast retrieval of data and reduce response time, best practices include leveraging materialized view support, bitmap indexing, result caching, and optimized queries, among other things. Equally important for reliable performance is to ensure automated and cost-effective scaling of compute resources to meet the changing analytics needs.
In a dynamically evolving healthcare landscape, the need for an integral approach to managing the growing volume of health data is high. And data warehousing is becoming vital to providing high-quality care and decreasing operational costs.
A lot goes into building a reliable and highly performant clinical data warehouse that meets the needs of the modern healthcare industry. An effective data warehouse design is rooted, among other things, in seamless aggregation of various data sources, the right data modeling approach, optimized query performance, and reliable security and privacy controls.





